What is ChainBench-ADD?
Existing audio deepfake datasets have greatly expanded evaluation across generators, languages, and domains, but most remain generation-centric and provide limited support for studying post-generation delivery. In realistic misuse scenarios, forged audio is often altered by platform re-encoding, telephony transmission, or replay-like recapture before it reaches a listener or an automated system. Recent delivery-related studies usually model such factors as isolated distortions rather than structured, ordered delivery routes, and often lack control over transcript and speaker conditions.
ChainBench-ADD addresses this gap by treating post-generation delivery as a structured benchmark dimension. It models delivery through reusable operators, ordered templates, and realized chains across five delivery families: direct, platform-like, telephony, simulated replay, and hybrid. Each delivered sample remains linked to a clean bona fide or spoof parent under matched-parent control, enabling attribution of detector behavior specifically to delivery rather than to differences in content, speaker, or source quality.
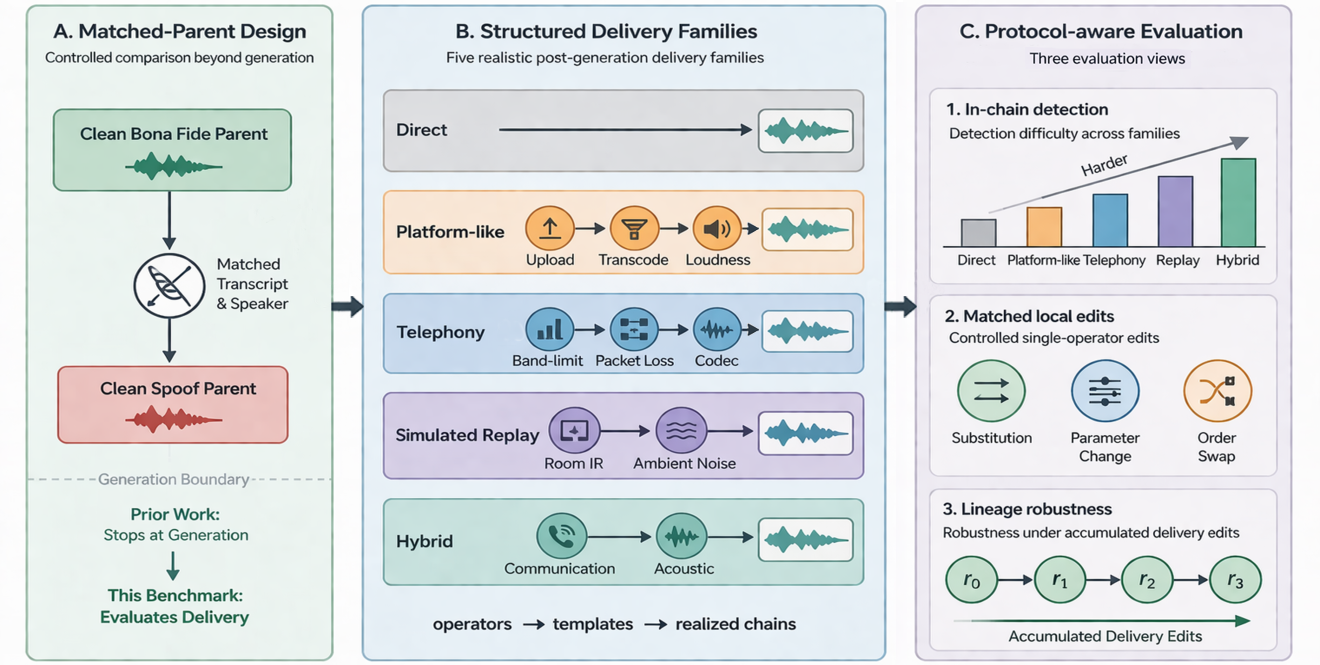
The current release contains 941,201 waveforms derived from 55,813 parents (18,703 bona fide from Common Voice and AISHELL-3; 37,110 spoof from six contemporary TTS systems) across 448 speakers in English and Mandarin Chinese. From the shared metadata, we define five evaluation tasks: in-chain detection, three matched local interventions (operator substitution, parameter perturbation, and order swap), and lineage-based delivery robustness. A leave-one-template-out protocol further tests transfer to unseen templates within a family.